Well-designed indoor scenes should prioritize how people can act within a space rather than merely what objects to place. However, existing 3D scene generation methods emphasize visual and semantic plausibility, while insufficiently addressing whether people can comfortably walk, sit, or manipulate objects. To bridge this gap, we present a Behavior-Aware Anthropometric Scene Generation framework. Our approach leverages vision–language models (VLMs) to analyze object–behavior relationships, translating spatial requirements into parametric layout constraints adapted to user-specific anthropometric data.
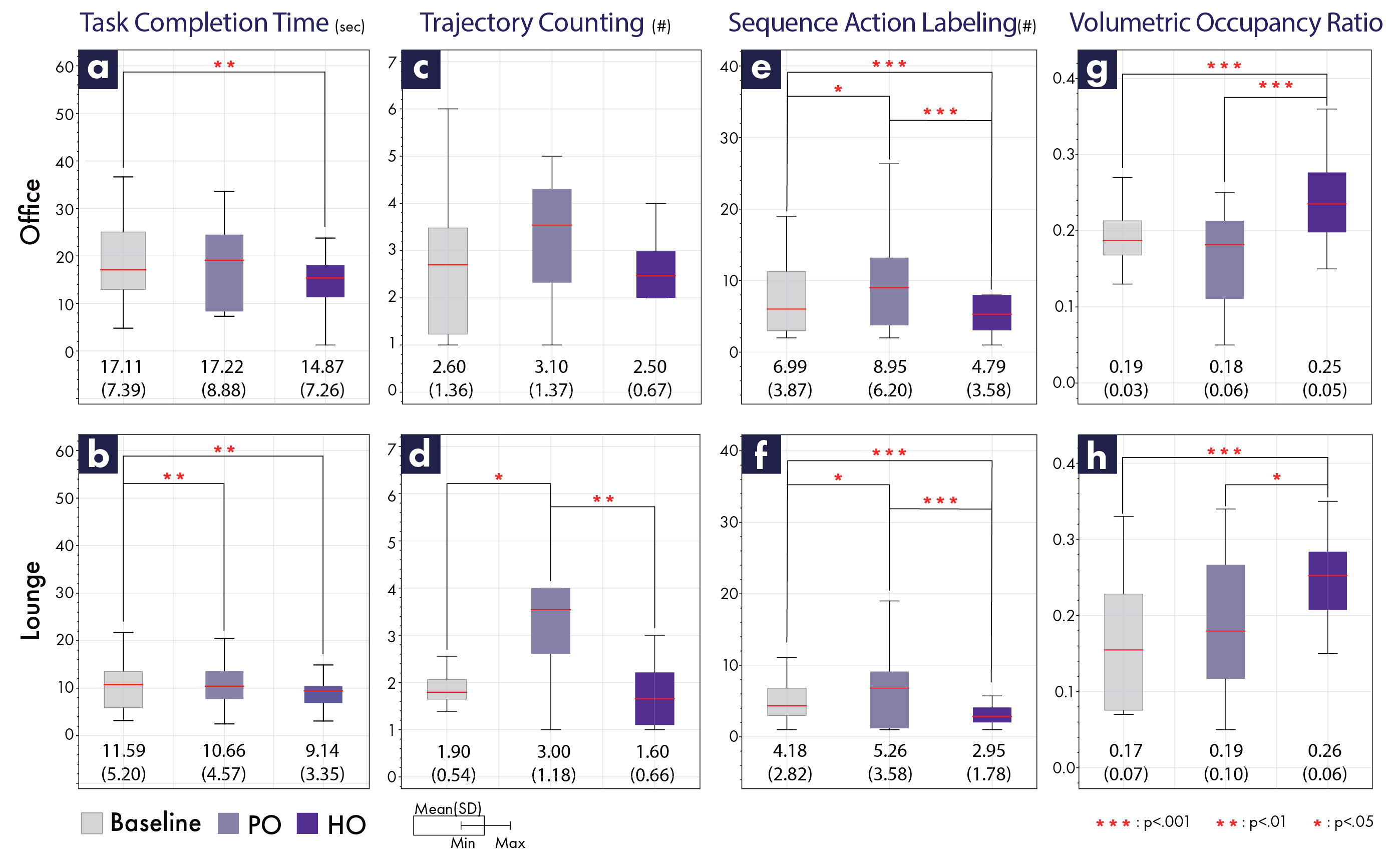
We conducted comparative studies with state-of-the-art models using geometric metrics and a user perception study (N=16). We further conducted in-depth human-scale studies (individuals, N=20; groups, N=18). The results showed improvements in task completion time, trajectory efficiency, and human–object manipulation space. This study contributes a framework that bridges VLM-based interaction reasoning with anthropometric constraints, validated through both technical metrics and real-scale human usability studies.
Four ideas drive the framework. They map onto the method but are not the method itself — the method has seven stages organized into two phases (see below).
Plan how people will act in a room before deciding where objects go. Function precedes geometry, so layouts are evaluated by what users can do in them — not by what they look like.
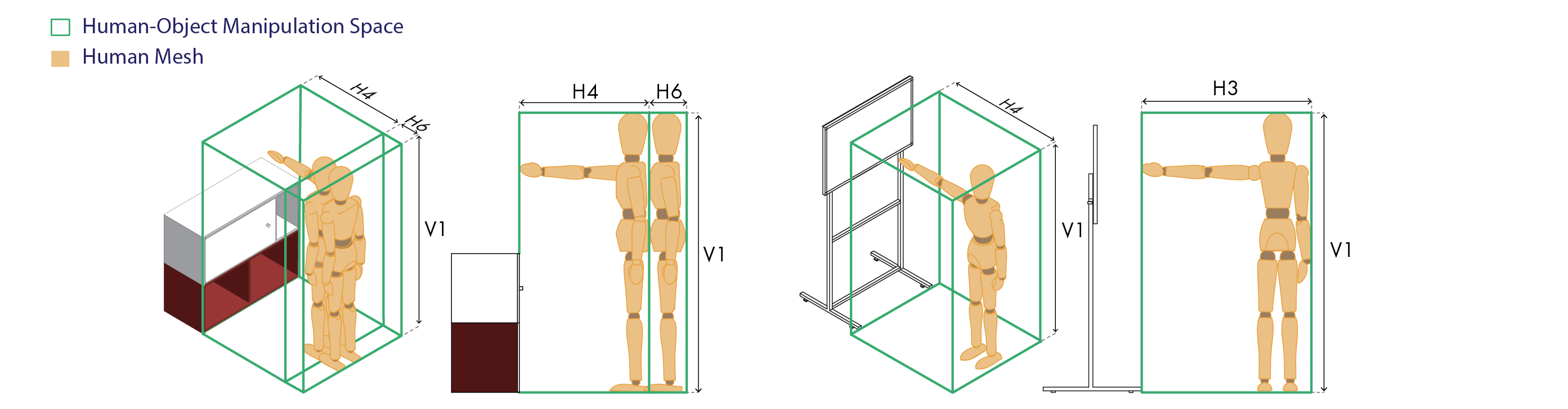
Every spatial constraint scales with the user's body — vertical height V1, horizontal reach H3, H4, drawing on 5th–95th-percentile anthropometric ranges rather than a single average individual.
A VLM reads object affordances from multi-view renders; an LLM clusters them into functional zones and writes the constraint program. The pipeline is language-model native end-to-end.
Real participants perform tasks in an 8-camera mocap studio. We measure time, detours, action chains, and the volume their bodies actually fill — not just survey scores.
Click each step to explore how behavior and anthropometry are turned into solved layouts.
The paper organizes the framework into two phases covering seven stages (A–G). Click each phase to expand its stages.
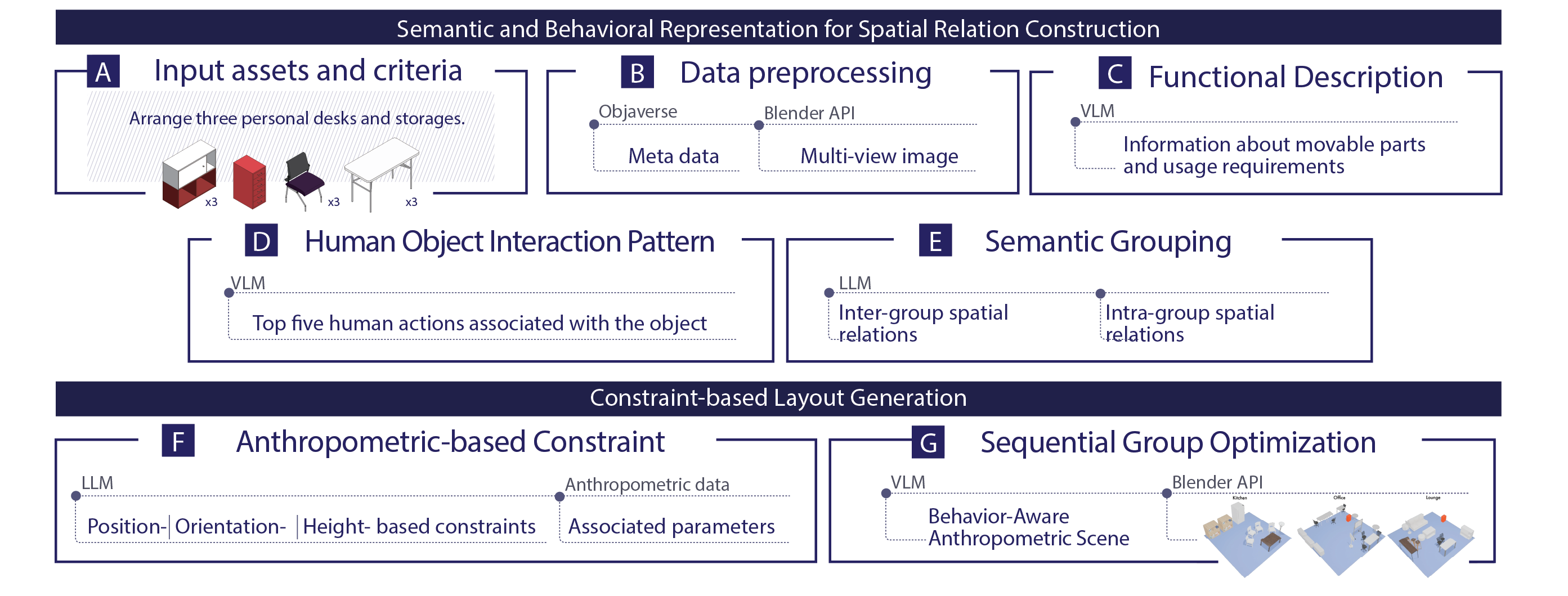
Five stages (A–E) that turn raw assets into a structured, behavior-tagged scene description.
The user supplies the asset set and a natural-language criterion.
criterion: "Arrange three personal desks and storages."
assets: { desk ×3, chair ×3, drawer ×3, … }Assets are retrieved from Objaverse using OpenShape, then processed through a scripted Blender pipeline that extracts a 3D bounding box and category / width / depth / height metadata, and renders each object from four orthogonal viewpoints (0°, 90°, 180°, 270°). Local coordinates are standardized as +X right, +Y forward, +Z upward.
The VLM takes the multi-view images + metadata and produces a structured JSON capturing qualitative information about movable parts and usage requirements — e.g., movement axes, articulation points, and kinematic constraints that are not evident in static category labels.
Illustrative output (fields per Figure 3):
{
"category": "drawer",
"description":"Rectangular drawer with a flat top.",
"width / depth / height (m)": [1.0, 0.4, 0.9],
"onCeiling": false,
"onWall": false,
"onFloor": true,
"front view": 0
}
// + free-form note, e.g.:
// "A front panel door slides horizontally along the X axis
// across the upper compartment.
// Keep the front face clear for side-to-side access."The VLM identifies the top five human actions a user is likely to perform with the asset, drawn from a library of atomic visual actions (e.g., sit, open, pull). For the example drawer in Figure 3, the inferred actions are:
e.g., a door
an object
an object
an object
e.g., a door, a box
The set of five differs per object — the carousel shows the drawer example from Figure 3.
Objects are organized into functional groups reflecting how humans interact with them — e.g., chairs around a desk forming a workspace, or sofas arranged around a coffee table creating a lounge area.
The LLM then emits two relation types:
Atomic actions from Stage D are reinterpreted in group context: an atomic open or pull (an object) becomes the higher-level relation organize when understood within a multi-cabinet storage group. Each group also receives a behavioral priority (e.g., scene-defining elements like beds or desks are placed first) that is used to reduce optimization complexity in Stage G.
Group names follow Figure 4E.
Two stages (F–G) that compile the behavior tags + anthropometry into a solvable program and produce the final scene.
Each natural-language relation (e.g., Office Chair facing Desk for intra-group, Double Chest maintains adequate distance from Desk for inter-group) is parsed and assigned to one of three constraint types — positional, orientational, or height-based (Table 1 in the paper).
Distance constraints are expressed as a center-to-center range [d_min, d_max] with d_accessibility = minimum reach distance and d_clearance = space needed for operational movement (e.g., pulling a chair). The tolerance buffer τ is inferred by the VLM from object function and interaction context.
Constraint taxonomy (ours vs. LayoutVLM [35]):
| Type | Name | Anthropometric rationale |
|---|---|---|
| Position | L_distance(pi, pj, d_min, d_max) | Bounds inferred from reach & clearance. |
| Position | L_against_wall(pi, wj, bi) | Accessibility for nearby interactions. |
| Orientation | L_align_with(pi, pj, Θ) | Task-oriented alignment. |
| Orientation | L_point_towards(pi, pj, Θ) | Preferred viewing / interaction direction. |
| Height | L_on_top_of(pi, pj, h) | Vertical stacking with sufficient interaction area. |
Anthropometric parameters are drawn from Human Dimension and Interior Space [28] using 5th–95th percentile ranges for forward reach, lateral reach, body breadth, and body depth — not from a single average individual. Examples shown in Figure 9: V1 (vertical height), H3, H4 (horizontal reach).
Each constraint is converted into a differentiable penalty (distance constraints penalize deviation from [d_min, d_max]; orientation constraints penalize deviation from the inferred alignment angles). The objective L = ∑i wi · violationi(θ) is minimized for 400 gradient-based iterations, with adaptive weighting that prioritizes collision avoidance when bounding-box overlap exceeds 50%.
Optimization proceeds sequentially by group: intra-group violations are minimized first, then inter-group constraints anchor each new group to the previously placed ones. The final layout is rendered in Blender as a Behavior-Aware Anthropometric Scene.
The optimization structure follows LayoutVLM [35]; the contribution lies in the behaviorally and anthropometrically grounded constraints fed into it.
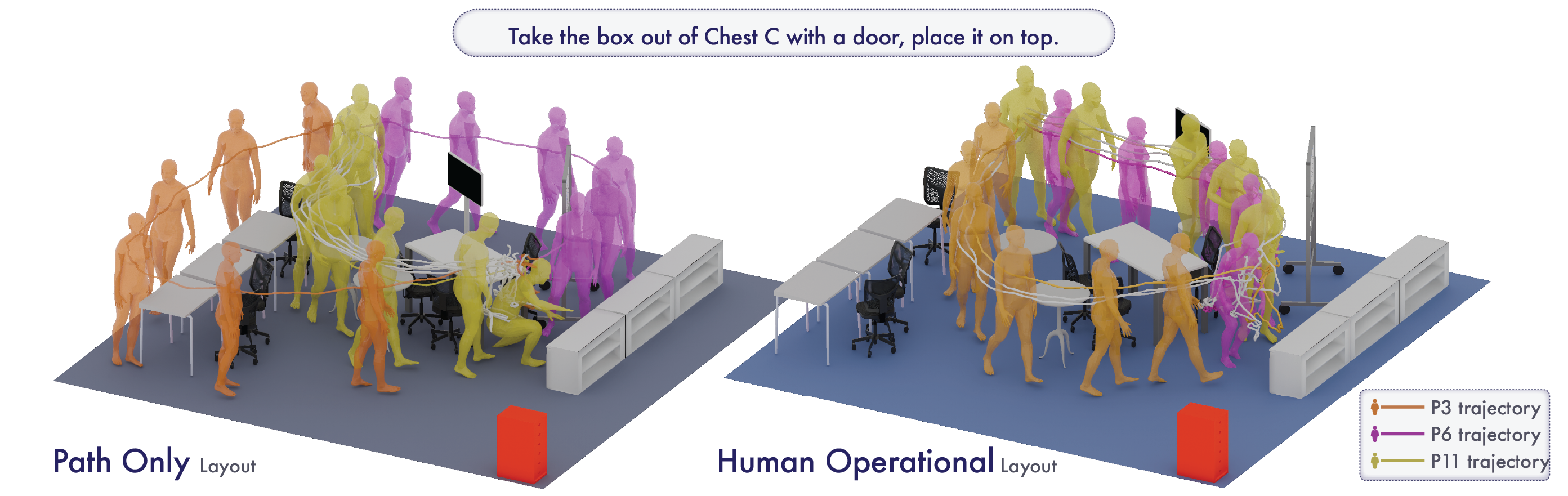
A per-action 3D bounding volume sized by the user's anthropometry that must stay collision-free for the action to be physically achievable. Reserving this volume — not just a navigable 2D passage — is what separates Human-Operational layouts from Passage-Only approaches.
We compare three layout conditions across Office and Lounge scenes under both individual (N=20) and group (N=18) sessions, plus a perception study (N=16).
How quickly participants finished the assigned task.
Distinct path branches per participant — fewer detours, clearer wayfinding.
Action-state transitions during the task — lower means a cleaner action chain.
Fraction of the reserved manipulation volume actually filled by the participant's body.
Across both Office and Lounge scenes, HO significantly reduced completion time, trajectory count and sequence noise while raising volumetric occupancy — meaning the reserved space is actually used.
@inproceedings{jin2026behavioraware,
author = {Jin, Semin and Kim, Donghyuk and Ryu, Jeongmin and Hyun, Kyung Hoon},
title = {Behavior-Aware Anthropometric Scene Generation for Human-Usable 3D Layouts},
booktitle = {Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems},
series = {CHI '26},
year = {2026},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
location = {Barcelona, Spain},
doi = {10.1145/3772318.3790341},
url = {https://doi.org/10.1145/3772318.3790341}
}